由于caddy官方脚本无法下载caddy v1,该方法暂时失效,新解决方案:翻墙软件NaiveProxy搭建
视频相关:
naiveproxy官方 https://github.com/klzgrad/naiveproxy
ProxySU官方 https://github.com/proxysu/windows
NaiveGUI官方 https://github.com/ExcitedCodes/NaiveGUI
补充内容:
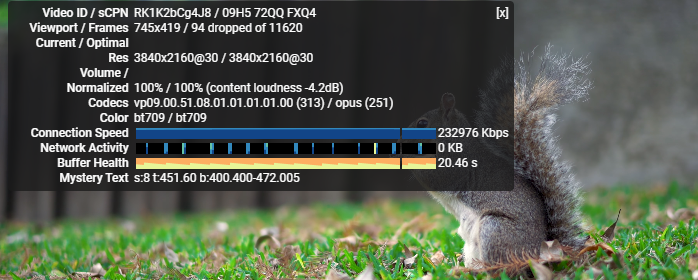
网友在电信300m带宽下使用谷歌云服务器(centos7)访问youtube4k视频的测速反馈结果
推荐使用bbrplus加速,另外在部署工具proxySu中的“伪装网站“尽量填写更增安全性,填写后,访问你的域名会跳转到你所填写的网站上去。
一键安装BBR/暴力BBR/魔改BBR/BBRplus/锐速 (Lotserver)四合一的脚本如下(两行内容一起复制粘贴):
wget -N --no-check-certificate "https://raw.githubusercontent.com/chiakge/Linux-NetSpeed/master/tcp.sh" && chmod +x tcp.sh && ./tcp.sh
(以下内容摘自美博园网站)
NaiveProxy的独到之处
正如美博教程所述:NaiveProxy是比较新的代理项目,与trojan类似也采用HTTPS协议,但有其独到特点,NaiveProxy可减轻流量指纹识别(特征)、主动探测和数据包长度分析的GFW审查带来的风险,就是说更难被墙检测和封锁。而且,设置比v2ray、trojan还要简略一些。
据官方介绍:NaiveProxy 使用Chrome的网络堆栈来伪装流量,与自定义的网络堆栈(如:Shadowsocks、V2Ray,手工Golang堆栈)相比,具有更强的抗审查能力和更低的可检测性。复用Chrome堆栈使得NaïveProxy在(代理)性能和安全方面有最佳的表现。
NaïveProxy可缓解以下几种方式的流量攻击:
# 网站指纹识别/流量分类:通过HTTP/2中的流量复用来缓解。
# TLS参数指纹识别:因复用Chrome的网络堆栈而不能识别。
# 主动探测:被前端应用所克制,即将代理服务器隐藏在具有应用程序层路由的常用前端后面。(美博注:这应是指反向代理)
# 基于数据包长度的流量分析:通过长度充填来减免。
NaiveProxy 使用Chrome的网络堆栈,GFW墙(审查器)拦截的流量行为与Chrome和标准前端(例Caddy,HAProxy)之间的常规HTTP/2流量相同,没有特征信号。前端还会将未经身份验证的用户和活动探针重新路由到后端HTTP服务器,从而使得无法检测到代理的存在,即:探测Probe → 前端服务器 → index.html(网页)。(美博注:这个部份在v2ray、trojan也都有实现)
正因为其抗指纹识别的独到之处,有人测试比较过几种代理的TLS指纹,结果NaiveProxy独领风骚。

 您的位置:
您的位置: